
Moving government into the cloud turned out all about asking the right questions. The arguments against had been around for many years, and put doubt in the minds of those with more traditional attitudes to IT. Is the cloud secure, is data safe? Many of these questions were the result of the disparity in experiences and conceptual understanding of the change between running in-house servers and running cloud infrastructures. Luckily as time has moved on, understanding and experience has moved in tandem, and these questions are not as commonplace. As we go from asking whether or not cloud technologies are the ‘right way’ for government we begin to ask more practical questions, such as, what is the ‘good way’ to run government in the cloud?
Moving out of the basement

A few years ago the Ministry of Justice began to take its first steps in changing the way it created and operated its services to citizens. One of the key guiding principles was that it would be cloud first, new services would be designed specifically to live in cloud environments and infrastructure would be architected to harness the benefits. Given the relative immaturity of some of the technology around at the time such as docker, what was achieved was pretty impressive. Inside of a core government ministry a truly cutting-edge cloud platform was put together. All the new services were built as containerised components, deployed automatically to our cloudformation, config managed, and docker fuelled platforms. We shifted our outlooks and embraced looking at our servers as ephemeral EC2 compute resources completely removed from our S3 and RDS persistence storage. All live services required the ability to have any of their servers destroyed without notice, with no alerts and no user impact. We were also quick to understand the value of freeing people from maintenance, data security, and disaster recovery that key managed services like Amazon RDS gives.

Figure 1 - A classic container service in the AWS cloud. Redundancy, self-healing, scaling groups across multiple availability zones, and a few managed components such as RDS and S3.
All of this cloud automation gave us some strong scalability, a small team was capable of running large groups of services, but to move to the next level would need something more. Providing so many key services with the needed reliability over long time-scales and without linearly scaling staffing is not a trivial thing. Even with high degrees of automation, maintaining a growing infrastructure places a burden on an organisation that can hold it back from achieving its core aim, developing and providing people with the digital services they need from modern government. With the experience of day-to-day operations at scale in the cloud, we surveyed what we had, what we felt was missing, and what we could have given the present.
No More Bricks

Operating at real scale requires moving up a level in the way we view our platform architectures. As engineers we want to place each brick, to have each server, each package configured the way we want it to be. As the number of bricks grows, we become more and more bogged down with maintaining and applying configuration. Each bug, each alert calls on a highly experienced engineer to investigate and fix. Simply enough, there is not enough people or money to go around as we grow to hundreds of services. In the present day though, it doesn’t have to be this way. By focussing on the higher level compute and persistence requirements of our platforms we can abstract away the time-consuming detail of how that’s achieved. But when we talk about moving up a level of detail, what exactly does that mean in practice?
One of the big changes in the last few years is the expansion of cloud hosting providers away from replicating real servers and infrastructures into the cloud. IAAS no longer necessarily means virtual machines and hard drives, but container services, serverless functions, and elastic storage. By shifting our thinking in a similar way we can build platforms that are both conceptually closer to what we are actually trying to achieve with our services, and also take much of the management duties of that functionality away.
We asked ourselves the question, what would an Amazon AWS managed component only platform look like? What would it give us in terms of functionality, reliability, management costs, and higher-level capabilities? Perhaps we could do everything we wanted to without building a thing, solely by setting out templates and hooking them together. Linking together the AWS Code* family of tools and ECR to replace our ever expanding Jenkins and Docker Registry services. Wrapping ECS with Application Load Balancer targets that replicates our current custom container service. Binding Route53 domains and automated Certificate Manager stacks to provide for full production services through nested stack templates. With all the pieces in place, our production service codebase can be replaced with a one-click AWS managed service.
Designing Cities

We offload the management of lower levels of the stack every time we turn on a laptop. We rely on the underlying pieces to do what needs to be done so we can focus on what we need to do. We don’t create a new desktop windowing system for each new application, the burden of that extra work would prevent us from ever creating anything novel or useful. In the same way, offloading the management of compute, persistence, and other functionality means that we can focus on the things we actually want to do, both as application developers, but also as engineers. We can focus on designing cities rather than placing each brick individually.
So, what can we do with this new capability and freedom from lower level work? Firstly, we can automate much more than ever before. We already have auto-scaling groups working with load balancer health checks that will self-heal our instances, but with voluminous data flows and solid cloudwatch basis to work with, we can implement higher level logic in our automation. Cloudwatch alarms on live service logging streams and rule-based cloudwatch events on infrastructure notifications mean we can set Lambda actions that will respond to complex behaviours on our services. With these tools we drive towards the deprecation of the run book, replacing it with the codifying of all human responses to live events into machine logic responses instead. We specify our security policies in AWS Config, and we specify our live responses through that Cloudwatch-Lambda workflow.
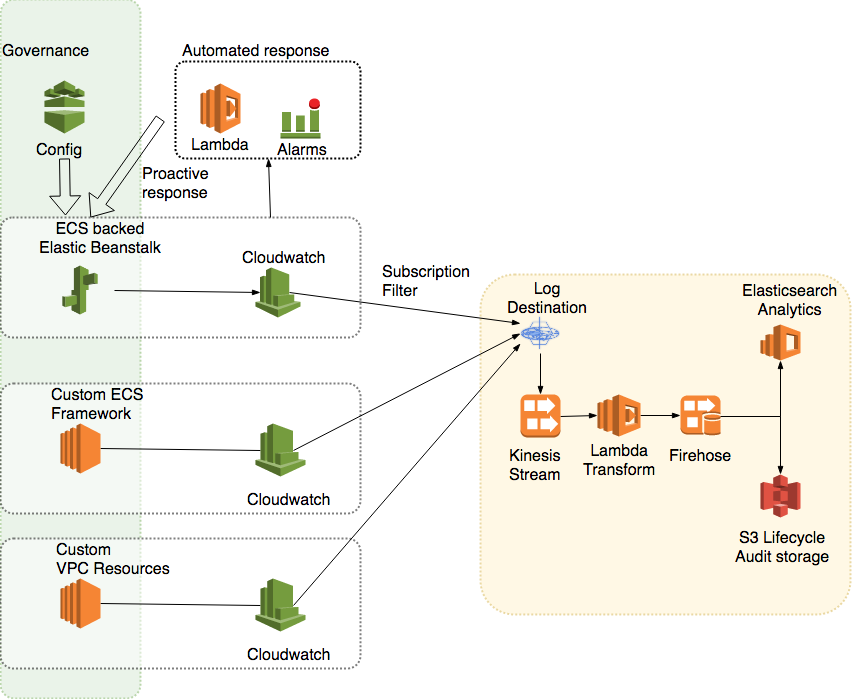
Seeing the horizon

Another benefit of moving up a level is to allow us greater visibility across the entire digital estate in operation, both the virtual infrastructure and the temporal. Utilising the inherent and comprehensive metrics and logging capabilities of AWS means automating complex per-service and aggregated service response logic. But there is more we can do. The addition of data pipelines unifies this knowledge and combines it into more in-depth analysis pools. Again by making good use of off the shelf AWS advanced components we can link together cloudwatch subscriptions, destinations, and Kinesis pipes to easily create resilient and high throughput delivery streams to analysis and aggregation functions. Streaming and combining our service metric data means we can easily utilise powerful Elasticsearch Service visualisations that gives us insight on broad spectrum service behaviours and possible security attacks. The Athena analytics tool takes this live service data and means that we pull S3 log data and query and visualise it to understand the broader behaviours of services as a whole. Taken further we could apply the off-the-shelf Machine Learning capabilities of AWS to move beyond the automation of responses to live service events and into the understanding of more subtle or dispersed patterns across all our services as a whole.
Essential Scalability

The point of all this technology is not to simply enjoy playing with the latest and greatest toys. All of our technology choices must be driven by real-life need, both to make the best of the limited resources available, and to provide for the availability that citizens need from their government. Government digital services are not often defined by a few large sites with millions of users. They are instead defined by thousands of smaller services, each meeting a specialised, often critical, need to the people using them. This is what utilising the power of the cloud truly gives, reliable government at scale.
By making our applications containerised our services themselves stay platform agnostic, meeting our needs of transferability and flexibility in the commercial world. But, this should never block us from making use of the power of hosting providers higher level tools and components. They act to free us up from standard low-level toil and focus on higher level functions. They give us the ability to standardise and make whole all of the fragments of government and keep them all running well with the minimum manual effort. And it is by leaving behind placing bricks and moving towards building these digital cities that we can realise our goals of running government at scale.









