The goal here is to implement an instance cycling task, resulting in all current instances being replaced with new instances with no downtime. When working with auto-scaling groups, its important to remember that the auto-scaling group is in control! Simply rebooting will most likely spook the scaling group into replacing the downed instance.
There’s a number of different ways to work around this,
- De-registering the instance from the ASG, doing our work, and re-registering. This might depend on what our auto-scaling policy wants though, not all policies will react when an instance goes missing, some will take action.
- Creating a new auto-scaling group, waiting for service-up on those instances, attaching it to the ELB and detaching the old. This has the benefit of working ‘offline’ to get a service up and being able to test and assure that service before switching it in.
Both of the above encourage treating current instances as stable components that should be looked after. There is a simpler way of course, treat those instances as disposable, temporary things that are in no way special, and are completely replaceable with any other instance.
The Minimal Solution
So why not simply, scale out to get new instances, and kill the old. The way this is achieved in bootstrap-cfn is,
- Scale-out, getting the new ubuntu AMI with security updates and salt installing new stuff too
- Once Autoscaling is complete, check that new EC2 instance is ‘good’ by checking the ELB health check after the autoscaling groups healthc check grace period is passed.
- Terminate old instance to return to desired instance count
The pain points in working with the auto-scaling group are
- ASG sets new instance to Inservice/Healthy when EC2 checks pass, not when service is actually good on that instance.
- So the ASG only calls the ELB healthcheck after the HealthCheckGracePeriod, which is arbitrarilly chosen.
So we only know we’ve been successful after…
- We start new instance
- The EC2 healthcheck passed
- The HealthCheckGracePeriod has expired
- The ELB healthcheck passed
- Now the service is actually up!
The ASG Lifecycle
Below is an example flow of the cycling process,
Step 1 - Creating the new instance
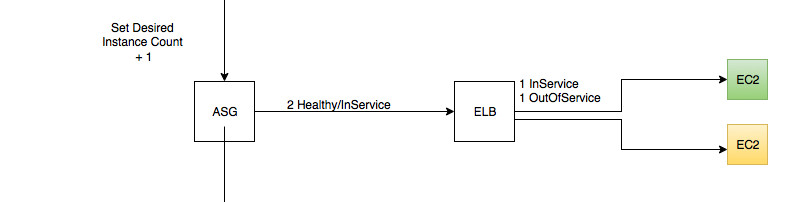
- Scale out the ASG by one
- New instance goes from pending -> in service and healthy
- ASG has new instance as in-service and healthy
- EC2 Healthcheck has been passed
- ELB has instance out-of-service as no health check passed
Step 2 - First attempt to get an serviceable instance up fails
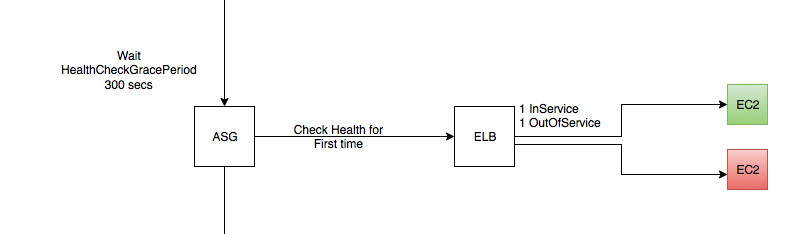
- Waiting for grace period before checking ELB health check
- ASG checks ELB health check for the first time
- Health check fails, EC2 instance is terminated
Step 3 - Trying again to get a new instance up
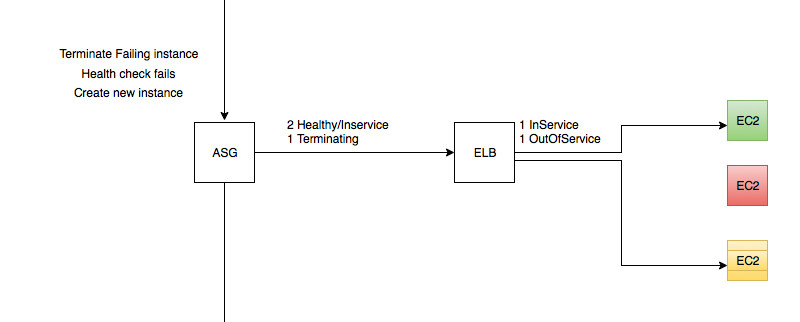
- Create new instance as before
- New instance has not passed health check yet
- New instance in healthy and on-service in ASG
Step 4 - Success! a new instance is up and the service on it is good
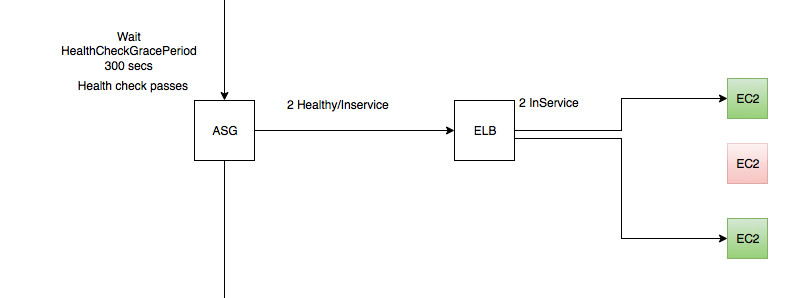
- This time, ELB health check has passed
- There are 2 healthy instances in the ELB
Step 5 - Out with the old
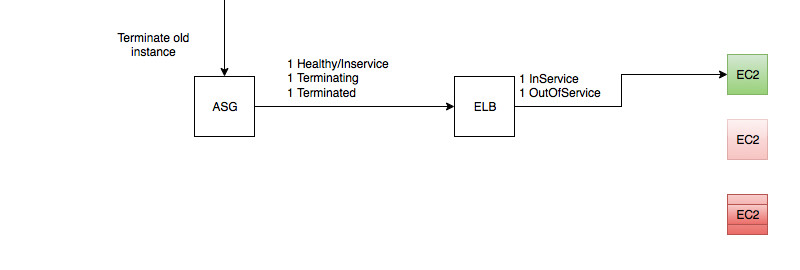
-
The new instance was created successfully
-
The old instance has been terminated
The Result
We now have a job that can safely cycle instances on a live production system with zero downtime of that service. But the main benefit is implicit in our treatment of our instances, individual instances are no longer valued, only the service matters. Introducing this approach helps to solve the updating problem, but by working with the auto-scaling group as our arbiter of instance persistence, and not against it by wresting control away and focusing our work on individual instances, we ensure that we are designing for the ephemeral nature of the cloud.
Next step? Automate everything 🙂









