Uncertain Futures
One of the most common challenges as businesses transform more of their traditional capabilities into digital ones is the breadth and depth of the change itself. Core changes to the organisational structure, processes, and culture. The functional components and interactions of these aspects of a large organisation help to define what we mean when we talk about complex systems. But it is also when we look through the lens of complex systems that we can get a different vision of change. Seeing it not as a disruption in so much as a possible instrument of stability and predictability. The rapidity of change not being something that is to be feared but instead something that can be embraced as a stabilising force. Complex systems concepts span a broad horizon as an abstraction of the behaviours of many disparate areas such as biological, computational and societal systems composed of many parts. Here we look at one small technological part and how understanding more of its behaviours as a complex system affects the ways we can view it and work in digital environments. To do this we’ll start by looking at the humble CICD pipeline…
Creating a solid, repeatable deployment pipeline is one of the first tasks in a any modern digital company. The benefits of rapid and frequent deployments and their ability to encourage robust software iterations has allowed development teams to deliver better code, faster, and in a more consistent way than ever before. Looking at the simple design of In Figure 1 we see a lot of common stages. At a high-level we have a build stage, unit testing, deployment to a development environment, integration testing, deployment to a staging or test environment, performance testing, and lastly deployment to production. More mature pipelines might have stages such as security scanning, fault injection, and so on.
Figure 1 - CICD simple pipeline
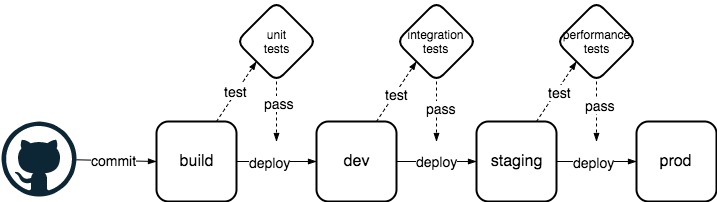
Pipelines can be powerful tools to reduce the risks of failed deployments, to code quality and system stability, and so mitigate against serious business problems being generated by the creation of new code. However, for the moment keeping it simple, we can shift perspective and look at things purely in terms of uncertainty and the reduction of unknowns.
Targets for a complex system
As increasing amounts of functionality within out businesses move online, the diversity and interconnectivity of the systems backing them have greatly increased too. We may have containers, virtual servers, serverless, on-premise, cloud, mainframes, monolith, microservice, and a myriad of other technologies and hardwares all communicating in a bunch of different protocols. Fundamentally these are now highly complex and dynamic systems, and are difficult to think of as a whole, and more so in terms of understanding real-time behaviours.
Within such a complex system there is a large state-space of possible configurations the environment may be in, and the actions or behaviours in those configurations. Whether we are given the job title SRE, System engineers, or DevOps, the goal is the same. We want to have the live systems configuration as close to the state we believe it to have, and we want the systems behaviour to be predictable to within a very narrow range.
System evolution and configuration drift
In the real world, there is always an element of configuration drift and the corresponding introduction of uncertainty in what we can reliably know about a system over time. Even assuming perfect knowledge of a system at time zero, how much can we truly say we know about our system at some arbitrary time in the future? And as the possible variance between our initial beliefs and subsequent predictions about the state and behaviour of the system, and those of the actual system escalates due to increasing uncertainties, what are the implications for the risks of applying either changes to the configuration to the system or even just relying on or reapplying the currently expected state.
Even when we make no changes over this period, hardware degradation, network instabilities, outlier inter-service communication patterns, human error, and any number of other factors can introduce change into the system. Change that is not captured in our knowledge about the systems configuration as we are unaware of it happening, or commonly the effects are so numerous in a large complex system that we cannot quantify them in sufficient time. As a result, the risk of unexpected behaviours increase, with the inevitable outcome that the system moves into configurations that are unreliable, sub-optimal, and at high risk of breaking.
A traditional reaction to this is to recoil from introducing more change. We have lengthy administrative procedures to gateway code changes and delay them for days or weeks or even months. Our processes are built specifically discourage changes to the system in the hope that the system will behave today exactly like it did yesterday, and we will avoid introducing instability. In simpler systems this can be understood to some extent, we have something we believe we can think off in its entirety and reason about in a contained and predictable way. The problem comes when we apply the same thought process to more complex systems. When we remove the introduction of external changes from a complex system what we are actually achieving is preventing the introduction of known well-defined configuration changes, and instead allowing unquantified system drift configuration changes to dominate the systems evolution.
Deployment pipelines as uncertainty reducers
With all the talk of complex systems, system configuration evolution, and the dynamic nature of uncertainty we can now look back at CICD pipelines and see them in a different light. Each stage in our pipeline is a way of constructing and quantifying known system configuration changes which, when deployed, will help to constrain the uncertainties in the system. Unit tests check that modular software elements behave in a well-understood way, the better the tests, the less uncertainty there is in the change. Our integration tests check that our predictions of the behaviour of services in the system will be accurate. Our performance testing reduces the uncertainty in the way the system will act under load and so on.
Figure 2 - CICD as uncertainty reduction
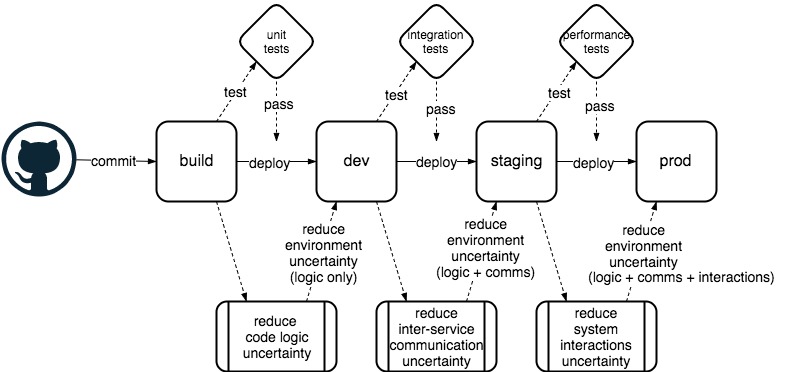
Looking back at our basic CICD pipeline in Figure 2 we see another way to visualise the pipeline transformations, to look at it from the point of view of uncertainty. At each stage of the CICD pipeline we apply some testing that acts to reduce the uncertainty we have about some aspect of the changes we are introducing. And in the act of moving the artifact into the next environment in the chain we are not only applying the initial change but also the uncertainty reduction from the testing process. As we move through the pipeline from left to right we iteratively apply a process of reducing the uncertainty of our changes, before applying them to the next environment alongside the actual change, with the effect being cumulative. In other words, by the time we deploy to production we are applying the originally built immutable artifact plus the sum of all the configuration and behavioural uncertainty reduction we have collected throughout the testing stages. The more accurate the testing scheme the more uncertainty is reduced for the aspect of the change being tested. The more aspects of the system we test throughout the pipeline the better the system testing coverage.
Containing uncertainty
With decent testing stages, the end change we make to our system will live within a small band of uncertainty. In making this change we remove the delta of uncertainty that has grown within the system over time, and replace it with the new. If we’ve done this all well, the uncertainty in our configuration change is actually less than the amount of uncertainty introduced by the system drift and we actually being more stability into the system by making the changes.
Figure 3 - System evolution, configuration drift against time for changing and unchanging systems
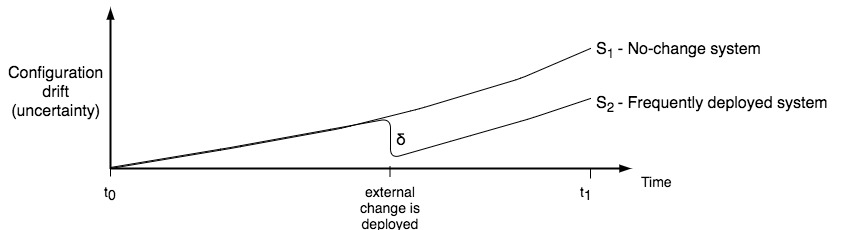
Figure 3 shows two systems evolving over time. The no-change system S1 gradually increases its configuration drift over time as random events, hardware malfunctions, network degradation, and application failures accumulate. While we have very accurate knowledge of the system at time t0, by time t1 there is a large amount of drift and our belief in the accuracy of our state knowledge of the system is greatly diminished. In practical terms this would mean that interacting with the system or making changes after time t1 would be very high risk as the behaviour of the system under perturbation of an external change is no longer accurately predictable.
Compare this with the frequently deployed system S2, the replica system to the previous one but now with the introduction of deployments of external changes into the system. The evolution of the system is identical to that of the no-change system until it reaches the point where an external deployment is made, where we introduce a well understood change into the system that has passed through our CICD testing pipeline and so has been tested well enough to limit the uncertainties carried in the configuration change. The outcome of deployment is to actually reduce the configuration drift of the system as we know more about the change we’ve deployed than the elements that have been replaced. Clearly the system is now more well understood in terms of behaviour and state than it was before the change was deployed. Once again this has practical outcomes in the sense that any further changes after this deployment carry a reduced risk in comparison to the no-change system. By making changes we have introduced more stability and predictability into the system, not less as is sometimes perceived.
Figure 4 - System evolution control through repeated change
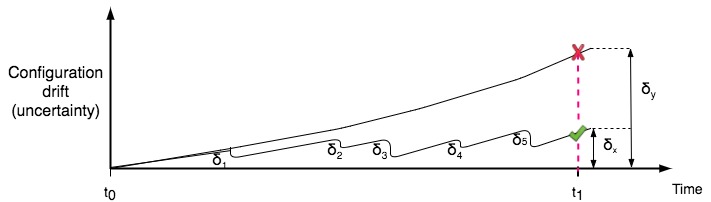
The overall effect of this is illustrated in Figure 4. We can see the same gradual drift of configuration certainty as before, but in this case we make multiple deployments of well-defined changes δ1 to δ5. This acts to repeatedly lower the uncertainty in the system and contain it within lower bounds. Meanwhile, the unchanged system uncertainty rises continually without any applied constraints. Finally at time t1 we make a change to both systems. The uncertainty in the unchanged system is large, and the behaviour of our change is unexpected. The systems stability is compromised and we have an operation and business threatening outage. However, since the drift in our certainty of the changing system is δx = δy - Σ δi and therefore δx « δy, we have a substantially reduced risk. Now the change falls within our range of predicted behaviours and system stability continues without any significant impacts.
As long as the analysis and testing of the applied changes δ1 to δ5 gives us less uncertain configurations than those in existence in the live systems, we will cumulatively benefit from those changes. The more we make, the safer we can predict and interact with the system. Note this forces a requirement of quality and coverage in our testing. If a system evolves over a time t to give us an uncertainty increase of δtsys overall. Then we can take the neighbourhood of impact of the change c to be the subspace of the target system that will be affected by our prospective change. If this subspaces uncertainty has increased by δtsub over this timeframe t then we must ensure that the uncertainties introduced by our change are δ < δtsub to benefit from the desired stability and predictability improvements.
Stability in change
It often feels counter-intuitive, and certainly goes against many peoples experiences with large non-complex systems, and so it bears repeating that the outcome of introducing well-defined changes into a complex system is enhanced stability. Digital businesses of any size are highly complex systems, and as such, will exhibit the growth in uncertainties caused by system drift to some extent or other. This property alone means that introducing well-tested changes with low uncertainties into complex production environments will improve stability, increase the predictability of its behaviour, and so reduces the risk of unexpected failures and outages.
There have been a number of large-impact systems failures seen in recent years, and as the complexity of digital systems grows ever more, the risk and impact of these is only likely to grow. Now more than ever embracing this understanding is key to any business that is looking to succeed in world of fast paced digital change. This can be a challenging belief to diffuse as it is often an antithesis to the practices that were successful in the past. Those successful practices when applied to the complex systems of the modern world however have the diametrically opposite effect to that which would be expected, and bring closer the danger of a catastrophic system failure in the future.